

By Dr. Saurabh Katiyar, Ph.D.
Published on SaurabhNotes.com
Introduction
Recent headlines have claimed that Z.ai (GLM-4.x) has become the world’s No. 1 open-weight AI model, based on LM Arena rankings.
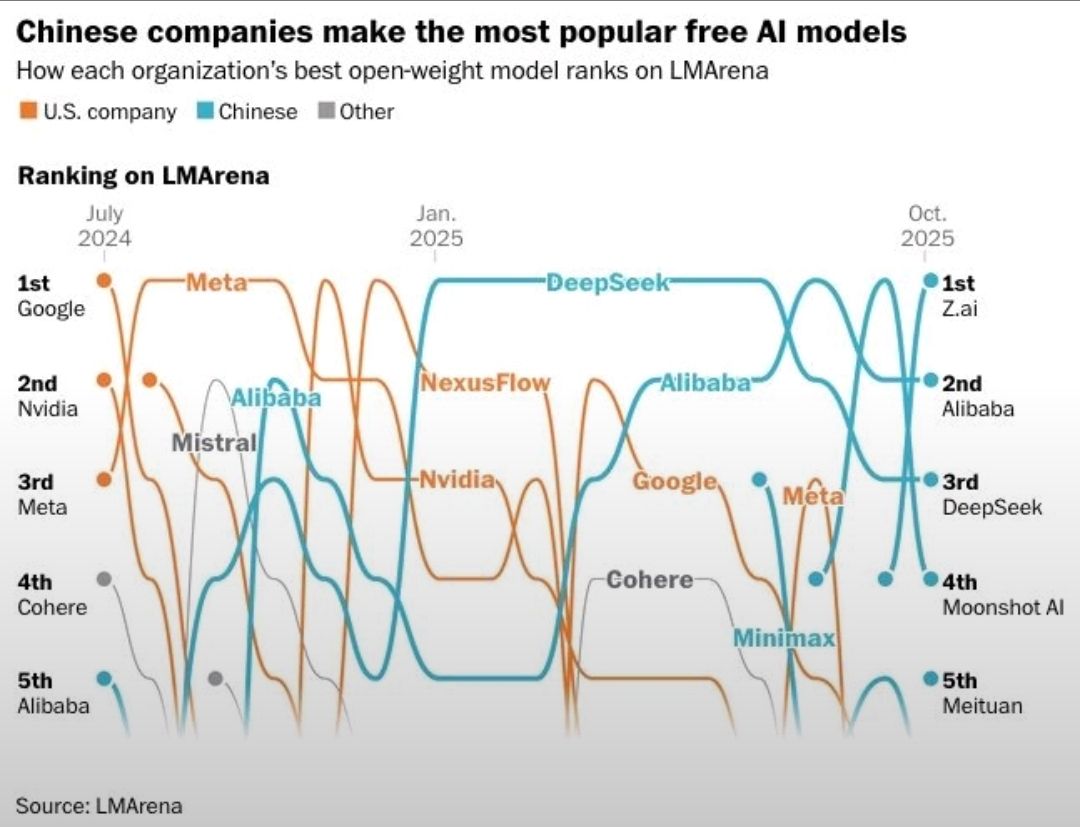
Such claims make for compelling news — but as scientists and technologists, we must separate signal from noise.
In this article, I explore three aspects:
- What LM Arena actually measures (and what it doesn’t).
- How leading open-weight models — from China, the US, and Europe — truly compare on independent benchmarks.
- What these developments mean for the future of trustworthy, transparent, and sovereign AI ecosystems.
Every statement below is grounded in public data or peer-reviewed sources — not speculation.
What LM Arena Really Measures
LM Arena uses crowdsourced human votes to rank models based on conversational preference. Users compare responses side-by-side, and Elo-style scores are computed from aggregated votes. While valuable for gauging user satisfaction, this method does not equate to technical superiority.
A 2025 analysis noted that LM Arena results are susceptible to sampling bias and model exposure — popular models get more comparisons and thus more votes. (Ars Technica, May 2025)
Therefore, LM Arena rankings reflect popularity and usability, not standardized reasoning or performance capability.
Complementary and More Objective Evaluations
- Hugging Face Open LLM Leaderboard — measures MMLU, GSM-8K, BBH, and ARC across open models.
- ArtificialAnalysis.ai Leaderboard — aggregates 100+ models on intelligence, speed, and cost.
- Inclusion Arena (Wang et al., 2025) — introduces real-world contextual evaluation to reduce leaderboard bias.
These benchmarks are far better at revealing a model’s reasoning depth, coding accuracy, and multi-language generalization.
Comparing Leading Open-Weight Models (2024–2025)
| Model | Highlights (data-based) | Limitations / Notes | References |
|---|---|---|---|
| DeepSeek V3 / R1 | Outperforms Gemini and GPT-4-class models on authorship and citation tasks in academic tests. | Slower inference; some gaps vs. Claude 3. | arXiv:2502.03688 |
| Alibaba Qwen 2.5 / 3 | Vendor-reported to surpass DeepSeek V3, GPT-4o, and Llama 3.1 405B in internal tests. | Independent peer review pending. | Reuters, Jan 2025 |
| Meta Llama 3 / 4 | Continues to dominate on MMLU and reasoning tasks; 405B variant as open baseline. | Criticized for benchmark tuning bias. | The Verge, 2025 |
| Mixtral 8×7B (MoE) | Efficient sparse-expert architecture; strong math and code performance. | Routing complexity, latency overhead. | arXiv:2401.04088 |
Key takeaway: There is no single model that dominates all axes — reasoning, code, alignment, multilinguality, and latency. Each model family optimizes for different trade-offs between compute cost, performance, and openness.
Understanding the “Z.ai #1” Claim
- Leaderboard snapshot ≠ universal truth. Zhipu AI’s GLM-4.5 variants may have topped a sub-category briefly, but no archive shows it as #1 overall (as of Oct 2025).
- Popularity ≠ benchmark leadership. Models tuned for conversational flow often rank higher on LM Arena but may lag on standardized tests.
- Verification matters. Always cross-check leaderboard claims with quantitative benchmarks (MMLU, MT-Bench, Arena-Hard).
Thus, Z.ai’s progress is not disputed — but the “#1” label should be read as context-specific, not absolute.
Emerging Trends and Scientific Insights
1. From Monolithic Models → Modular Ecosystems
Future architectures will combine core backbones + domain adapters + verifier models, enabling specialization without retraining entire networks. (arXiv 2503.04765)
2. Hybrid Openness Will Prevail
Expect “governed openness”: partial weight releases, usage licenses, and sovereign-AI frameworks (as seen with Meta’s and Alibaba’s releases).
3. Real-World Benchmarks Will Replace Static Tests
Next-gen frameworks like Inclusion Arena embed evaluation in real applications, reducing leaderboard gaming (Wang et al., 2025).
4. Rise of Sovereign & Transparent AI
Countries increasingly demand self-hostable AI stacks for privacy and security — open-weight models enable this trend.
5. Trust and Explainability as Core Metrics
Future AI leadership will depend not only on accuracy but also on auditability, interpretability, and bias transparency.
Conclusion
The AI landscape is shifting from competition over single “best” models to collaborative ecosystems of transparent, sovereign, and trustworthy intelligence. The real victory lies in benchmark integrity, reproducibility, and open scientific dialogue.
Z.ai’s rise — alongside DeepSeek, Qwen, Llama, and Mistral — symbolizes a positive trend: AI innovation is now truly global.
